Teaser
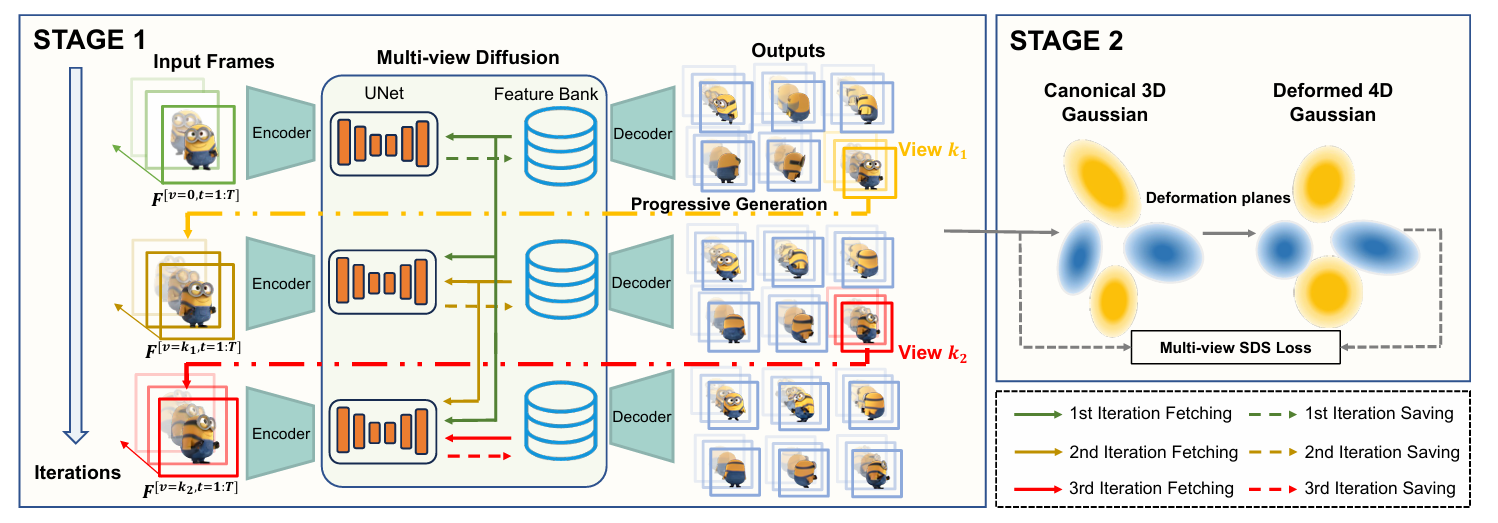
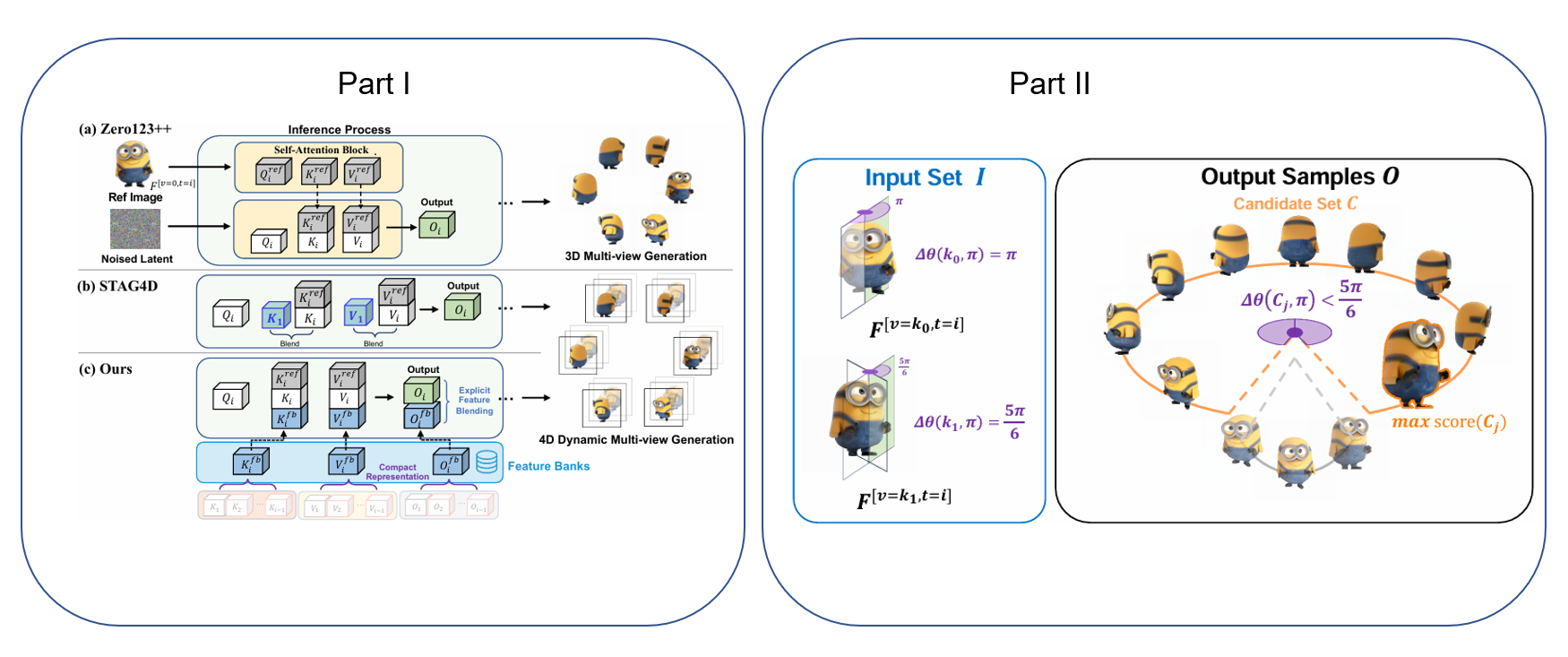
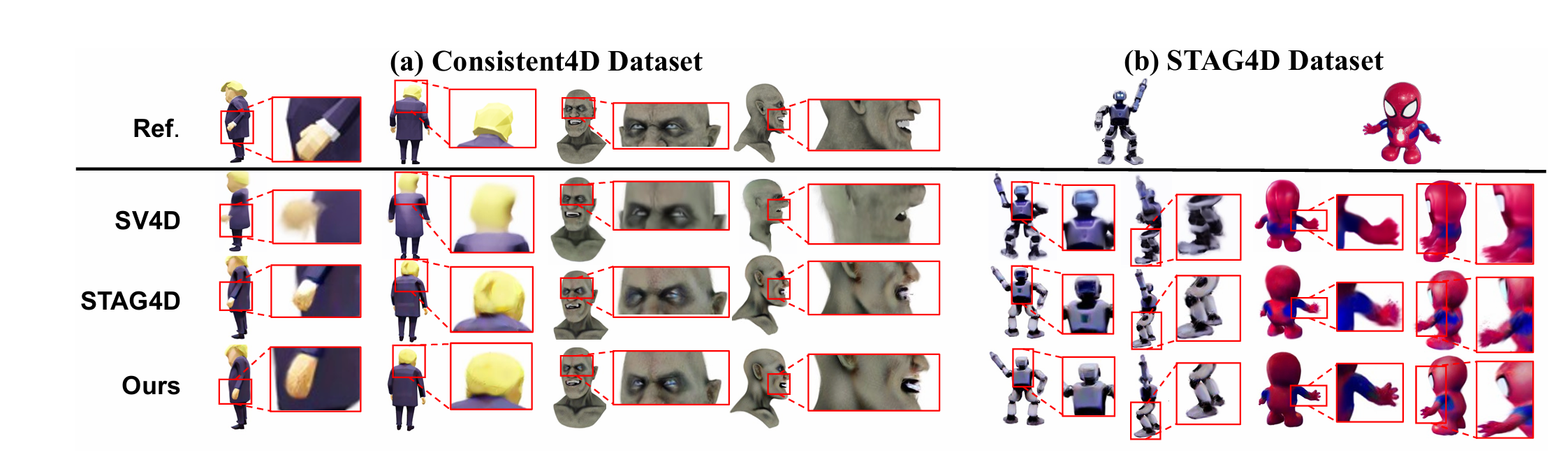
With the rapid advancements in diffusion models and 3D generation techniques, dynamic 3D content generation has become a crucial research area. However, achieving high-fidelity 4D (dynamic 3D) generation with strong spatial-temporal consistency remains a challenging task. Inspired by recent findings that pretrained diffusion features capture rich correspondences, we propose FB-4D, a novel 4D generation framework that integrates a Feature Bank mechanism to enhance both spatial and temporal consistency in generated frames. In FB-4D, we store features extracted from previous frames and fuse them into the process of generating subsequent frames, ensuring consistent characteristics across both time and multiple views. To ensure a compact representation, the Feature Bank is updated by a proposed dynamic merging mechanism. Leveraging this Feature Bank, we demonstrate for the first time that generating additional reference sequences through multiple autoregressive iterations can continuously improve generation performance. Experimental results show that FB-4D significantly outperforms existing methods in terms of rendering quality, spatial-temporal consistency, and robustness. It surpasses all multi-view generation tuning-free approaches by a large margin and achieves performance on par with training-based methods. Our code and data will be publicly available to support future research.

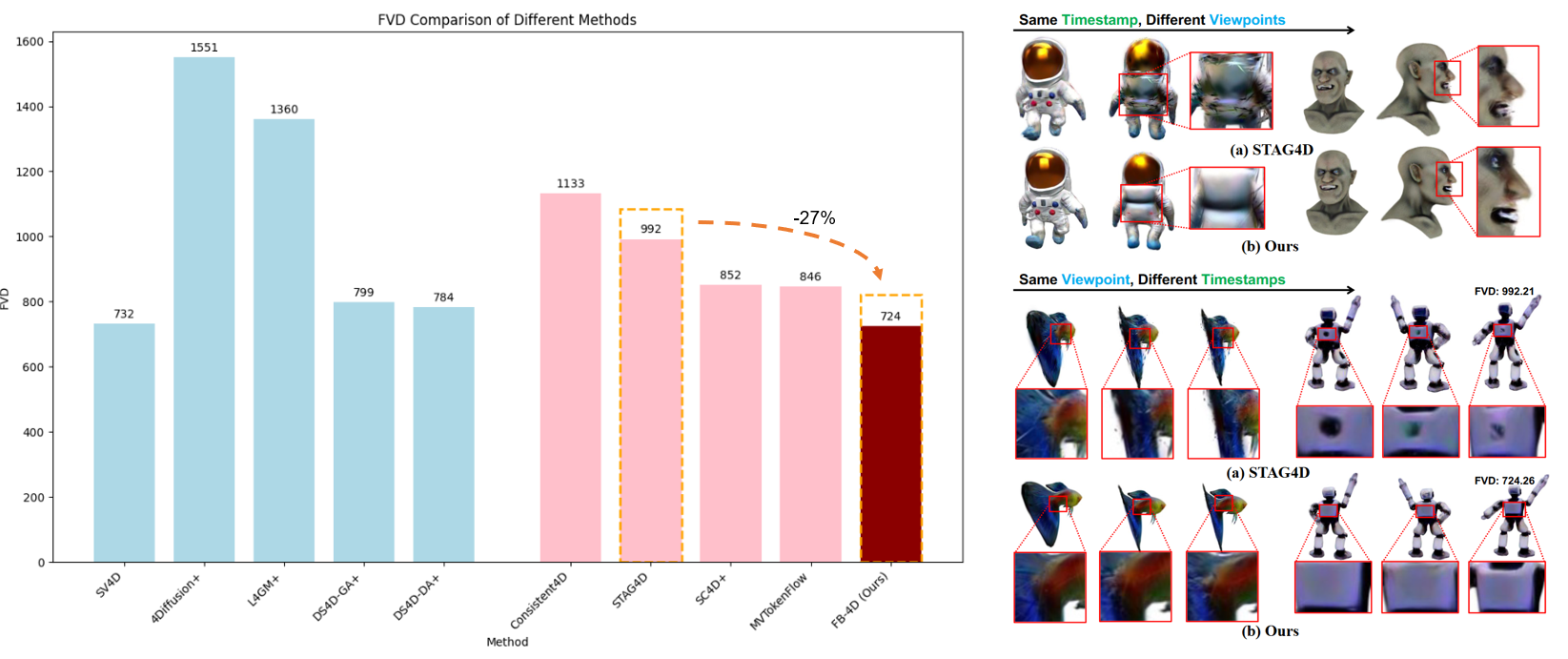
| Method | T-F | FVD (↓) | CLIP (↑) | LPIPS (↓) |
|---|---|---|---|---|
| SV4D | ✗ | 732.40 | 0.920 | 0.118 |
| 4Diffusion+ | ✗ | 1551.63 | 0.873 | 0.228 |
| L4GM+ | ✗ | 1360.04 | 0.913 | 0.158 |
| DS4D-GA+ | ✗ | 799.94 | 0.921 | 0.131 |
| DS4D-DA+ | ✗ | 784.02 | 0.923 | 0.131 |
| Consistent4D | ✔ | 1133.93 | 0.870 | 0.160 |
| 4DGen | ✔ | - | 0.894 | 0.130 |
| STAG4D | ✔ | 992.21 | 0.909 | 0.126 |
| SC4D+ | ✔ | 852.98 | 0.912 | 0.137 |
| MVTokenFlow | ✔ | 846.32 | 0.948 | 0.122 |
| FB-4D (Ours) | ✔ | 724.26 | 0.913 | 0.125 |
@misc{li2025fb4dspatialtemporalcoherentdynamic,
title={FB-4D: Spatial-Temporal Coherent Dynamic 3D Content Generation with Feature Banks},
author={Jinwei Li and Huan-ang Gao and Wenyi Li and Haohan Chi and Chenyu Liu and Chenxi Du and Yiqian Liu and Mingju Gao and Guiyu Zhang and Zongzheng Zhang and Li Yi and Yao Yao and Jingwei Zhao and Hongyang Li and Yikai Wang and Hao Zhao},
year={2025},
eprint={2503.20784},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.20784},
}